
VAMP / time-lagged CCA¶
For users already familiar with the VAMP interface: The corresponding API docs.
VAMP [1] is short for [V]ariational [A]pproach for [M]arkov [P]rocesses. It can be used as linear dimensionality reduction tool and extends TICA in the sense that it gives rise to a systematic way to select input features as well as handles off-equilibrium data consistently. The method is a form of canonical correlation analysis [2] (originally presented in 1935) in time, also called time-lagged canonical correlation analysis (TCCA).
While the VAMP model possesses methods to project data into lower dimensions, it also is equipped with scoring functions (the so-called VAMP scores), which allow ranking of features. This has been demonstrated in, e.g., [3].
In order to estimate a VAMP model, a Koopman operator \(\mathcal{K}_\tau\) is estimated, which describes conditional future expectation values for a fixed lag time \(\tau\). Its action on a function \(g\) can be written as
where \(p(y \mid x)\) is the conditional probability density that a point \(y\) at time \(t+\tau\) is visited given that point \(x\) was visited at time \(t\). Making the ansatz that \(g\) is a linear combination \(g = \sum_i w_i \chi_i\) for some basis functions \(\chi_i\), the linear operator \(\mathcal{K}_\tau\) can be expressed as matrix \(K\). It can be shown [1], that the dominant eigenfunctions of an SVD of the Koopman operator in a whitenend basis \(\bar K\) yields the best dynamical model for a given timeseries, which is also what is computed and projected on in estimator and model, respectively.
VAMP deals with off-equilibrium cases consistently, which can be divided into three subcategories (as presented in [4]):
Time-inhomogeneous dynamics, e.g, the observed system is driven by a time-dependent external force,
Time-homogeneous non-reversible dynamics, i.e., detailed balance is not obeyed and the observations might be of a non-stationary regime.
Reversible dynamics but non-stationary data, i.e., the system possesses a stationary distribution with respect to which it obeys detailed balance, but the empirical of the available data did not converge to this stationary distribution.
The third of the described cases is salvageable with TICA when a special reweighting procedure (Koopman reweighting) is used.
Short API demonstration¶
To create a VAMP estimator, it needs to be imported and instantiated.
[1]:
from deeptime.decomposition import VAMP
vamp_estimator = VAMP(
dim=1 # projection dimension
)
One should note that the dim parameter can either be None, of type int or of type float:
if
None, all dimensions are kept,if of type
int(and>= 1), this is the dimension to project onto,and if of type
float(in the range \((0, 1]\)), then this is interpreted as a percentage value which is the minimum threshold of kinetic variance that needs to be explained by the projection.
Note that unless
None, even setting the dimension with an integer might yield a lower-dimensional projection than the one requested if there is a rank deficit in the covariance matrices.
For demonstration purposes, we look at the Ellipsoids sample dataset, which is described in some detail in the example data’s documentation. In short, it is a two-dimensional process that has two metastable states in the form of nonoverlapping ellipsoids.
[2]:
from deeptime.data import ellipsoids
# create dataset instance with fixed seed for reproducibility
ellipsoids = ellipsoids(seed=17)
# 1000 observations
feature_trajectory = ellipsoids.observations(1000)
print(feature_trajectory.shape)
(1000, 2)
Given the data, all that is left to do is to fit a model by providing covariances and obtaining it from the estimator or using fit on the timeseries directly. In the latter case, a lagtime must be provided.
[3]:
covars = VAMP.covariance_estimator(
lagtime=1 # the time lag with which the covariance matrices are estimated
).fit(feature_trajectory).fetch_model()
vamp_estimator.fit(covars)
model = vamp_estimator.fetch_model()
# ---- or ----
model = VAMP(lagtime=1, dim=1).fit(feature_trajectory).fetch_model()
The output dimension is set to 1:
[4]:
model.output_dimension
[4]:
1
And the model can be scored, which evaluates how much “slowness” is captured with the current input features. Scores can not be compared across different lagtimes \(\tau\).
[5]:
model.score(r=2)
[5]:
1.8534787431760964
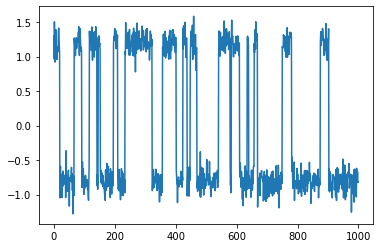
Projecting the 2-dimensional data with the estimated VAMP model yields a 1-dimensional trajectory which clearly reveals the two-state metastable process which generated the data:
[6]:
projection = model.transform(feature_trajectory)
print(f"Projection shape: {projection.shape}\n")
# plot projection
import matplotlib.pyplot as plt
plt.plot(projection);
Projection shape: (1000, 1)
A more detailed look on the estimator¶
Here we follow the content presented in [1] to give some more insight into the estimator. For a complete derivation and background please consult the source itself.
The VAMP estimator estimates a linear model of the form
where \(\tau > 0\) is the lagtime, \(f(x) = (f_1(x),\ldots)^\top\) and \(g(x) = (g_1(x),\ldots)^\top\) are feature transformations of the system’s state \(x\) at a point in time \(t\) so that the dynamics are approximately linear.
While the matrix \(K\) can in principle also be estimated using standard regression tools, the regression error gives no information about the choice of feature trasformations \(f\) and \(g\). When estimating \(K\) using VAMP, a meaningful scoring and thus cross-validation is available. For details on the available scores, see the Scoring section.
This matrix is actually a finite-dimensional approximation of the Koopman operator
which maps for given \(x_t\) observed through \(f\) to the expected value of an arbitrary observable \(g\) at time \(t+\tau\). This in particular means that the matrix \(K\) depends on \(\mathcal{K}_\tau\), i.e., models at different lagtimes approximate different operators and are thus not directly comparable.
One can show (Theorem 1 of [1]), that the best approximation of \(K\) to \(\mathcal{K}_\tau\) is achieved for
when \(f = (\psi_1,\ldots,\psi_k)\) and \(g=(\phi_1,\ldots,\phi_k)\). Here \(\sigma_i\), \(\psi_i\), \(\phi_i\) are the singular values, left singular functions, and right singular functions of \(\mathcal{K}_\tau^*\mathcal{K}_\tau\), respectively. The operator \(\mathcal{K}_\tau^*\mathcal{K}_\tau\) relates to a foward-backward mapping in time. The \(\psi_i\) and \(\phi_i\) should form an orthonormal basis of respective spaces. In particular this means that in this representation,
where \(\bar{\mathcal{K}}_\tau\) denotes the projected Koopman operator.
The VAMP estimator first and foremost solves the following problem:
Given a basis set \(\chi^\top = (\chi_0, \chi_1)^\top\) so that \(f = U^\top \chi_0\) and \(g=V^\top \chi_1\), find weights \(U,V\in\mathbb{R}^{m\times k}\) so that the resulting linear model \(\mathbb{E}[g(x_{t+\tau})] = K^\top \mathbb{E}[f(x_t)]\) is optimal. For the purposes of estimation the potentially different basis sets \(\chi_0\) and \(\chi_1\) are assumed to be equal. In practice one can achieve this by simply concatenating the observable trajectories in time.
When there are significantly more frames than dimensions in the dataset, the (instantaneous and time-lagged) mean-free covariance matrices \(C_{00}, C_{0t}, C_{tt}\) with
can be computed by the Covariances estimator. These covariance matrices can be accessed in the computed model:
[7]:
print("mean_0 shape:", model.mean_0.shape)
print("mean_t shape:", model.mean_t.shape)
print("C00 shape:", model.cov_00.shape)
print("C0t shape:", model.cov_0t.shape)
print("Ctt shape:", model.cov_tt.shape)
mean_0 shape: (2,)
mean_t shape: (2,)
C00 shape: (2, 2)
C0t shape: (2, 2)
Ctt shape: (2, 2)
Based on these covariances, the truncated SVD
is evaluated, where \(\bar K\) is the Koopman matrix for normalized basis functions \(C_{00}^{-1/2}\chi_0\) and \(C_{tt}^{-1/2}\chi_1\), respectively. The truncation is based on the dim parameter of the estimator.
The sought-after weight matrices \(U\) and \(V\) are then given by
respectively. The singular values as well as \(U\) and \(V\) are accessible as:
[8]:
print("singular values:", model.singular_values)
print("left singular vectors U:", model.singular_vectors_left)
print("right singular vectors V:", model.singular_vectors_right)
singular values: [0.92383913 0.02905651]
left singular vectors U: [[-0.39412183]
[ 0.40228095]]
right singular vectors V: [[-0.40095045]
[ 0.40235857]]
The resulting linear model
is then given by \(K = \mathrm{diag}(\sigma_1,\ldots,\sigma_k)\), \(f_i = u_i^\top\chi_0\), and \(g_i = v_i^\top\chi_1\).
The model’s transform(data, forward=True) gives access to \(f\) and \(g\):
[9]:
x = model.transform(feature_trajectory, propagate=False)
plt.plot(model.transform(feature_trajectory), label="f")
plt.plot(model.transform(feature_trajectory), linestyle=(0, (5, 10)), label="g")
plt.legend();
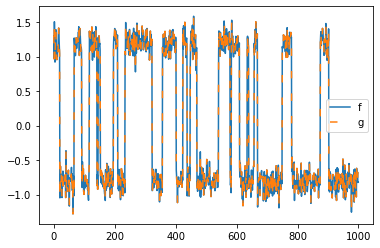
As one can observe, it makes no difference whether one projects \(x_t \mapsto f(x_t)\) (forward in time) or \(x_t\mapsto g(x_t)\) (backward in time). This is because the underlying process is time-reversible.
A consequence of this is that one should be aware of which data is provided into transform: Only
feature_trajectory[:-tau, ...]forf(i.e.,right=False) andfeature_trajectory[tau:, ...]forg(i.e.,right=True)
contain valid values, the remainder might be interpreted as extrapolation.
Scoring¶
While the estimator solves the problem of finding optimal transforms \(f\), \(g\), and \(K\), one of the advantages of using the variational approach is that the models can be scored with respect to the choice of the system’s featurization.
This makes it possible to not only optimize for transforms given a basis but also for the basis itself. If -hyothetically- infinite data and computational power were avaiable, the best possible basis would be the one that can describe the full operator \(\mathcal{K}_\tau\). In practice however, often a balance between the modeling/discretization error of approximating \(\mathcal{K}_\tau\) and the statistical error of fitting the parameters given finite data has to be struck.
There are three different typical scores implemented in deeptime:
[10]:
model.score(r=1)
[10]:
1.9238391327369158
The VAMP-2 score, evaluating the squared sum of the singular values \(s = \sum_i \sigma_i^2\), which maximizes the kinetic variance captured by the model [7]. It is also directly related to the approximation error to the true Koopman operator \(\mathcal{K}_\tau\) [1]. This is the default choice for scoring.
[11]:
model.score(r=2)
[11]:
1.8534787431760964
The VAMP-E score also relates to the approximation error to the true Koopman operator, however its computation is numerically more stable than VAMP-1 or VAMP-2, as it does not involve any matrix inversions [1].
[12]:
model.score(r="E")
[12]:
1.8534787431760968
Otherwise one can also evaluate any other score with r >= 1.
[13]:
model.score(r=3.3)
[13]:
1.7699596561010507
In addition to the score_method parameter, there is also a test_model parameter. By default it is None and the score is evaluated as-is. In case it is not None, the score() method evaluates the cross-validation score between the current model and test_model.
It is assumed that the model and the test_model stem from respective “training” and “testing” datasets. Estimation of the average cross-validation score and partitioning of data into test and training part is not performed by this method.
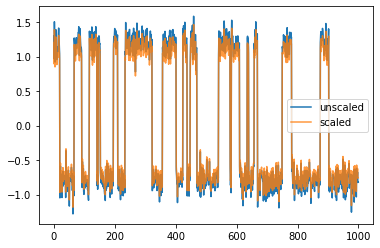
Singular vector scaling¶
Optionally the singular vectors can be scaled upon projection. Per default, scaling is set to None which means that no scaling is applied and the variance of all singular vectors (sometimes also called order parameters) is \(1\).
[14]:
print(vamp_estimator.scaling)
None
One has the option to set it to "kinetic_map", which means that the singular vectors are scaled by their respective singular value. As a result, Euclidean distances in the “left singular vectors”-transformed data approximate kinetic distances with respect to the forward propagator. Vice versa, a kinetic map is induced when using scaled right singular vectors and the backward propagator.
[15]:
vamp_estimator.scaling = "kinetic_map"
scaled_model = vamp_estimator.fit(covars).fetch_model()
# plotting transformations
plt.plot(model.transform(feature_trajectory), label="unscaled")
plt.plot(scaled_model.transform(feature_trajectory), alpha=.8, label="scaled")
plt.legend();
Example with position based fluids¶
Here we demonstrate a toy dataset created by a position based fluids (PBF) simulator [8]. In a 2-dimensional simulation box we place particles which then relax to a resting density. We periodically disturb the equilibrium resting density by applying a force toward the left and right boundary of the simulation box alternatingly. For more details on the dataset, please refer to the example data’s documentation.
Here, we create a new PBF simulator with a predefined simulation box and set of initial positions:
[16]:
from deeptime.data import position_based_fluids
pbf_simulator = position_based_fluids(n_jobs=8)
It contains
[17]:
pbf_simulator.n_particles
[17]:
972
particles, which are equilibrated for 5000 simulation steps.
Now, we generate a trajectory with an oscillatory force acted upon the particles. Each oscillation round contains two sets of the force applied toward the left simulation box border and right simulation box border, respectively for 400 steps each.
[18]:
trajectory = pbf_simulator.simulate_oscillatory_force(n_oscillations=7, n_steps=400)
We visualize the trajectory with a matplotlib animation under a stride of 30:
[19]:
animation = pbf_simulator.make_animation(trajectory, stride=30, mode="scatter", figsize=(5, 4))
from IPython.display import HTML
HTML(animation.to_html5_video())
[19]:
Since the trajectory just contains the x-y coordinates of the particles, it is in \(\mathbb{R}^{T \times 2\cdot \mathrm{n\_particles}}\).
[20]:
print(trajectory.shape)
(5600, 1944)
For the purpose of estimating a VAMP model on this trajectory and analyzing the slow motions, the trajectory is featurized using a Gaussian KDE:
[21]:
n_grid_x = 20
n_grid_y = 10
kde_trajectory = pbf_simulator.transform_to_density(
trajectory, n_grid_x=n_grid_x, n_grid_y=n_grid_y, n_jobs=8
)
This featurized trajectory can be visualized similarly:
[22]:
animation = pbf_simulator.make_animation(kde_trajectory, stride=30, mode="contourf",
n_grid_x=n_grid_x, n_grid_y=n_grid_y, figsize=(5, 4))
HTML(animation.to_html5_video())
[22]:
A VAMP model can be estimated like below.
[24]:
model = VAMP(lagtime=100).fit(kde_trajectory).fetch_model()
Afterwards, we can project with the left and right eigenfunctions
[25]:
projection_left = model.forward(kde_trajectory, propagate=False)
projection_right = model.backward(kde_trajectory, propagate=False)
And visualize also these.
[26]:
import numpy as np
tau = model.cov.lagtime
n_sing = 3
f, axes = plt.subplots(ncols=3, nrows=n_sing, figsize=(n_sing*5, 13))
f.suptitle("Lagtime {}, VAMP-E score {:.3f}".format(tau, model.score("E")))
for i in range(n_sing):
left = projection_left[:-tau][1600:5000, i]
right = projection_right[tau:][1600:5000, i]
axes[i][0].plot(np.arange(1600, 5000), left, label="left")
axes[i][0].plot(np.arange(1600, 5000), right, label="right")
axes[i][0].vlines([1600 + i*400 for i in range(1,8)],
np.min(left), np.max(right), linestyles='dotted')
axes[i][0].set_title(f"VAMP projection component {i+1}")
axes[i][0].set_xlabel("time")
axes[i][0].legend()
ax = axes[i][1]
im = model.singular_vectors_left[:, i].reshape((n_grid_y, n_grid_x))
cb = ax.imshow(im, origin="lower", cmap="bwr")
f.colorbar(cb, ax=ax)
ax.set_title("left eigenfunction {}".format(i))
ax = axes[i][2]
im = model.singular_vectors_right[:, i].reshape((n_grid_y, n_grid_x))
cb = ax.imshow(im, origin="lower", cmap="bwr")
f.colorbar(cb, ax=ax)
ax.set_title("right eigenfunction {}".format(i))
plt.tight_layout()
plt.show();
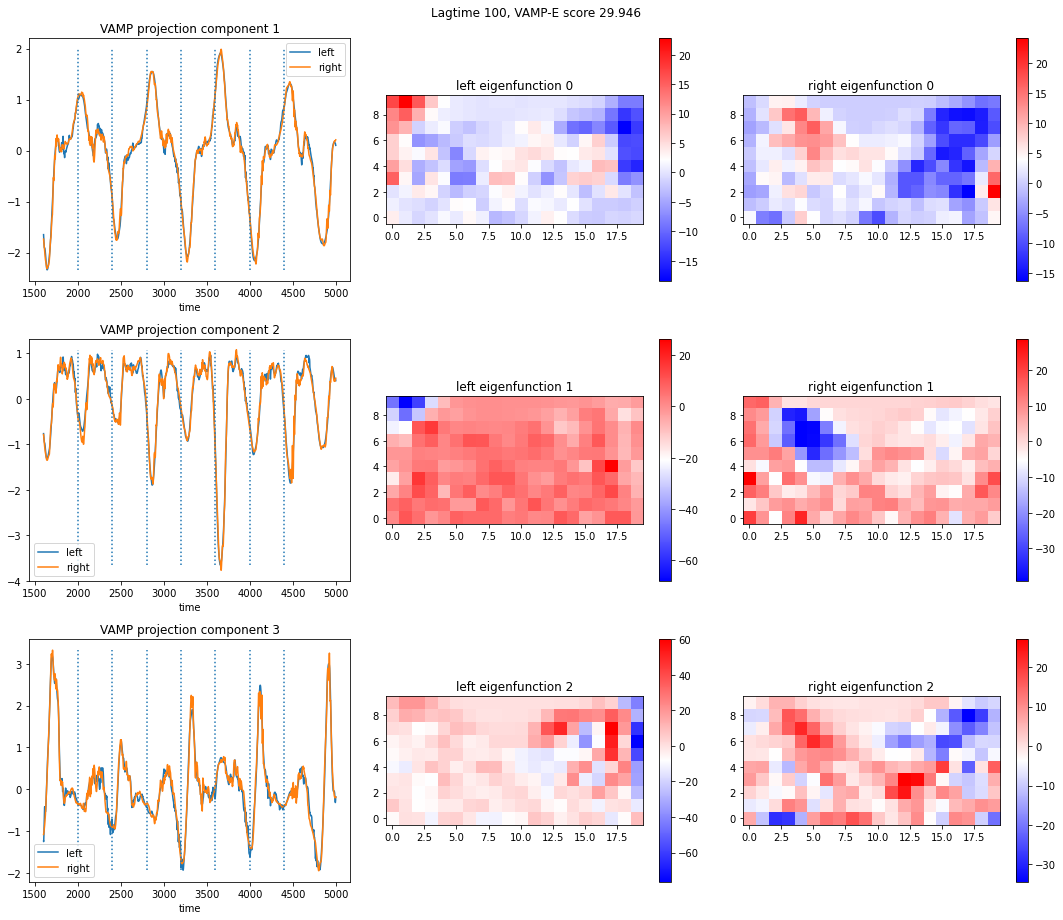
The dotted vertical lines are whenever the force changes direction. When looking at the intensity of the left and right eigenfunctions, areas that are of similar intensity in left as well as right can be considered “coherent”.
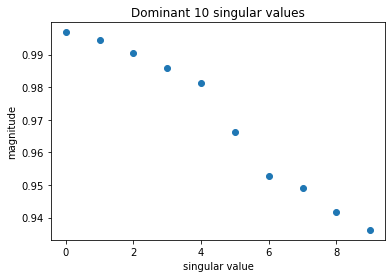
Further, left and right eigenfunction projections are same, which means that the process is reversible. In such a case the magnitude of the singular values should decay exponentially and one can look for a so-called spectral gap.
[27]:
plt.plot(model.singular_values[:10], 'o')
plt.title("Dominant 10 singular values");
plt.xlabel("singular value")
plt.ylabel("magnitude")
[27]:
Text(0, 0.5, 'magnitude')
From the estimated linear model
we can also apply the forward operator to frames by calling propagate(). It also allows to project onto specific processes by setting all other singular values to zero.
It summary, it evaluates
[28]:
forward_full = model.propagate(kde_trajectory)
Here we show the result of the forward operation, i.e., propagating the left-hand side to its future (with \(\tau=100\)) expected value.
[29]:
animation = pbf_simulator.make_animation([kde_trajectory, forward_full], stride=30, mode="contourf",
n_grid_x=n_grid_x, n_grid_y=n_grid_y, figsize=(10, 4))
HTML(animation.to_html5_video())
[29]:
What becomes clearer in the projection onto single processes is that
the slowest process is associated with a density change from left <-> right
the second slowest process is associated with a density change middle <-> sides
This can also be seen in the plot of the 1-dimensional projection onto a specific component of the whitened space in above plot:
For the slowest process (component 0) there is a sign change roughly every 800 frames, for the second slowest process (component 1) it is roughly every 400 frames. The combination of the four dominant components shows some notion of a flow from left to right and vice versa and is therefore already quite close to the trajectory except for particle splashes.
[30]:
forward_component0 = model.propagate(kde_trajectory, components=0)
forward_component1 = model.propagate(kde_trajectory, components=1)
forward_component0123 = model.propagate(kde_trajectory, components=[0, 1, 2, 3])
[31]:
animation = pbf_simulator.make_animation(
[kde_trajectory, forward_component0,
forward_component1, forward_component0123
], stride=30, mode="contourf", n_grid_x=n_grid_x, n_grid_y=n_grid_y, nrows=2, ncols=2,
figsize=(10, 8), titles=["trajectory", "component 0", "component 1",
"dominant components 0, 1, 2, 3"])
HTML(animation.to_html5_video())
[31]:
References